The fitness function ![]() is used to direct the evolutionary process
into a certain direction. The genetic algorithm is in fact merely
a method of approximating the global maximum of
is used to direct the evolutionary process
into a certain direction. The genetic algorithm is in fact merely
a method of approximating the global maximum of ![]() in the
search space of chromosome strings. The actual interpretation
of this search space (the phenotypes) is packed into
in the
search space of chromosome strings. The actual interpretation
of this search space (the phenotypes) is packed into ![]() and doesn't
concern the algorithm itself.
and doesn't
concern the algorithm itself.
As mentioned in Section 3.2.1, the optimal choice for ![]() is in a linear
relation to the Hamming distance
is in a linear
relation to the Hamming distance ![]() to the optimal solution
to the optimal solution ![]() .
In a more general definition of linearity, problems are also refered
to as linear, when the following condition applies.
.
In a more general definition of linearity, problems are also refered
to as linear, when the following condition applies.
Nonlinearities in ![]() result in the slower convergence of the algorithm.
Due to its stochastic nature, the algorithm will always eventually
find a solution, but in some cases the number of necessary evaluations of
result in the slower convergence of the algorithm.
Due to its stochastic nature, the algorithm will always eventually
find a solution, but in some cases the number of necessary evaluations of ![]() can be greater than
can be greater than ![]() and the performance is worse then in a simple
systematic search of
and the performance is worse then in a simple
systematic search of ![]() .
.
In many cases, it is more natural to refer to the quality of an individual
by its error instead of its fitness and use the genetic algorithm to
minimises the error. As this is the case with neural networks, we will
occasionally replace the fitness function ![]() by the error function
by the error function ![]() .
.
A training set ![]() of a neural network is a set of pairs of a sample input
vectors
of a neural network is a set of pairs of a sample input
vectors ![]() and its associated output vector
and its associated output vector ![]() , which are
called training patterns. If
, which are
called training patterns. If ![]() is the
network function, then the error E of the network for the pattern
is the
network function, then the error E of the network for the pattern
![]() is defined as
is defined as
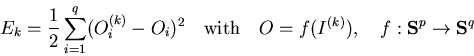
To use this definition for the genetic algorithm, the network (the phenotype)
must be decoded from the chromosome string. The decoding function ![]() is inverse function of
is inverse function of ![]() as defined in Section 2.4.4.
1
as defined in Section 2.4.4.
1
To calculate an error for all patterns, a mean value of all ![]() must be
calculated. If all patterns are of equal importance and a low sum of
all errors is more important than a small maximum error for each pattern,
then the arithmetic mean of all
must be
calculated. If all patterns are of equal importance and a low sum of
all errors is more important than a small maximum error for each pattern,
then the arithmetic mean of all ![]() should be returned.
should be returned.
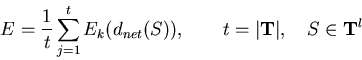
If the training set is very large and highly redundat, it is
possibel to estimate the error by evaluating only a subset
of ![]() which is changed for each generation.
(This can be seen as the genetic eqivalent to the
backpropagation online learning described in Section 4.1.1.)
which is changed for each generation.
(This can be seen as the genetic eqivalent to the
backpropagation online learning described in Section 4.1.1.)