One of the most common test problems to evaluate the performance
of network training algorithms is the XOR-problem.
To allow algorithmic comparisons, only the sequential versions
of the genetic ( cntseq -N2 -O1) and the backpropagation
algorithm ( cntback -N2 -O1) have been used.
(Since the training set consists only of the 4 patterns
![]() ,
, ![]() ,
, ![]() and
and ![]() ,
a parallel algorithm on a shared memory system would be of
rather low efficiency, anyway.)
,
a parallel algorithm on a shared memory system would be of
rather low efficiency, anyway.)
For the following measurements, the problem was considered to be solved, when the average error per pattern is less than 0.001. A program fails, after 100000 backpropagation steps or 10000 generations.
Four series of 10 simulations varying in learn method
(online or batch) and impulse factor (![]() or
or
![]() ) have been started and produced the
following results:
) have been started and produced the
following results:
| method | succeeded | avg. iterations | avg. time | ||
| 1 | 0 | batch | 8/10 | 5188.0 | 9.0 s |
| 1 | 0.9 | batch | 9/10 | 538.7 | 1.1 s |
| 1 | 0 | online | 6/10 | 1294.8 | 2.2 s |
| 1 | 0.9 | online | 7/10 | 138.0 | 0.3 s |
This figures show the limitation of backpropagation or any other
gradient descend method: One quarter of the started simulations
failed i.e. got trapped in a local minimum of the error
functions.
Also, the data illustrates the effects of the impulse
term with speedups about 900%, the value of the acceleration
factor ![]() (see Section 4.1.2).
Online learning is about 4 times faster than batch learning,
but leads to more than the double number of failures.
(see Section 4.1.2).
Online learning is about 4 times faster than batch learning,
but leads to more than the double number of failures.
Six series of 10 simulations varying in the numbers of
bits ![]() used for the encoding of the weights have been
started.
The standard genetic parameters (
used for the encoding of the weights have been
started.
The standard genetic parameters (![]() mutation,
mutation,
![]() crossover, population size 100, linear
rank selection) have been used.
crossover, population size 100, linear
rank selection) have been used.
| succeeded | avg. gen. | avg. time | |
| 4 | 10/10 | 20.7 | 2.5 s |
| 6 | 10/10 | 62.8 | 8.6 s |
| 8 | 10/10 | 51.7 | 6.7 s |
| 10 | 10/10 | 40.4 | 5.8 s |
| 12 | 10/10 | 33.0 | 4.7 s |
The most striking difference to backpropagation is, that all programs have succeeded, which illustrates the robustness of the genetic method, while backpropagation normally converges faster if it converges at all.
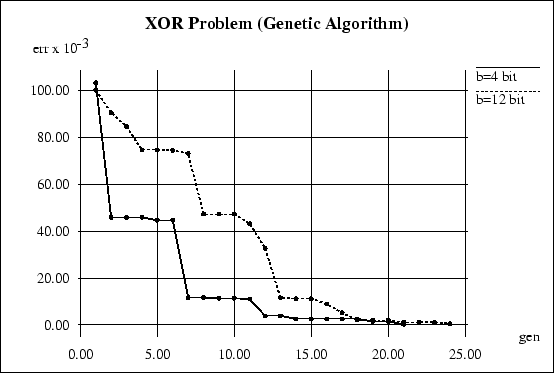
The impact of ![]() shows, that a more accurate
error function normally leads to better convergence,
except for very short encodings, where the
element of random search might outweigh this
effect. Fig. 3 shows the error graph
for two simulations with
shows, that a more accurate
error function normally leads to better convergence,
except for very short encodings, where the
element of random search might outweigh this
effect. Fig. 3 shows the error graph
for two simulations with ![]() and
and ![]() .
.