This section describes the distributed memory version of a parallel genetic algorithm for the training of neural networks as it has been implemented for a transputer network of 16 T800's.
The genetic algorithm consists of two main parts, the evaluation of the fitness and the fitness based selection and generation of a child population. The fitness evaluations for each individual are totally independent and can be thus be done in parallel with each processor holding his share of the global population.
The selections and the generation of a child population by genetic operators are also independent from each other, but there are three problems to exploit this parallelism on a distributed memory system:
It is therefor necessary to collect the individuals with their associated errors from all processors to one master processor, which performs those steps and redistributes the child population again in equal portions. 3
For a ![]() -
-![]() -
-![]() network with a training set of
network with a training set of ![]() patterns and
an encoding in chromosome strings of the length
patterns and
an encoding in chromosome strings of the length ![]() , the
computation/communication ratio
, the
computation/communication ratio ![]() is given by
is given by
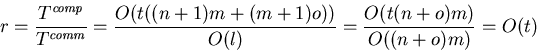
The ratio between the (parallel) error calculation and the (serial)
selection and genetic operations is also of order ![]() . Since
. Since ![]() is normally sufficiently high, this should allow an efficient
parallel implementation.
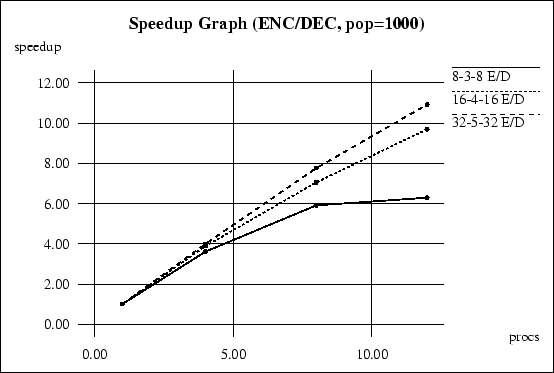
Fig. 2 gives the speedup graph for the parallel
implementation of the encoder/decoder problem (Section 6.2.1).
is normally sufficiently high, this should allow an efficient
parallel implementation.
Fig. 2 gives the speedup graph for the parallel
implementation of the encoder/decoder problem (Section 6.2.1).
To further improve the computation/communication ratio, it is possible to perform the global selection not for every new generation, but only after a certain number of local selections. This possibility is provided as an option in the parallel implementation. However, due to the negative impact on global covergence, the use of this method brings hardly any speedup.
The genetic algorithm involves only communications between master
and slaves, which should be reflected in an appropriate topology
of the transputer network. If each processor can be directly
linked to ![]() other processor, then the optimal topology is an
other processor, then the optimal topology is an
![]() -ary tree with the master as root. Since the used T800's
have four hardlinks, a ternary tree was used. To avoid
unnecessary idle times, also the master works on his own local
population.
(In the parallel implementation for this project even the
same sourcecode is used for master and slaves.)
-ary tree with the master as root. Since the used T800's
have four hardlinks, a ternary tree was used. To avoid
unnecessary idle times, also the master works on his own local
population.
(In the parallel implementation for this project even the
same sourcecode is used for master and slaves.)